
open函数
语法:
open(name[, mode[, buffering]])
解释:
- name : 一个包含了你要访问的文件名称的字符串值。
- mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
- buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
open函数的模式(mode):
- r:以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
- w:打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
- a:打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
- r+:打开一个文件用于读写。文件指针将会放在文件的开头。
- w+:打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
- a+:打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
- rb:以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。
- wb:以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
- ab:以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
- rb+:以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。
- wb+:以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
- ab+:以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
open函数的方法:
- fp.read([size]):size为读取的长度,以字符数量为单位,并不是以字节为单位
- fp.readline([size]):读一行,如果定义了size,有可能返回的只是一行的一部分
- fp.readlines([size]):把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。
- fp.write(str):把str写到文件中,write()并不会在str后加上一个换行符
- fp.writelines(seq):把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
- fp.close():关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。 如果一个文件在关闭后还对其进行操作会产生ValueError
- fp.flush():把缓冲区的内容写入硬盘
- fp.fileno():返回一个长整型的"文件标签"
- fp.isatty():文件是否是一个终端设备文件(unix系统中的)
- fp.tell():返回文件操作标记的当前位置,以文件的开头为原点
- fp.next():返回下一行,并将文件操作标记位移到下一行。把一个file用于for … in file这样的语句时,就是调用next()函数来实现遍历的。
- fp.seek(offset[,whence]):将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
- fp.truncate([size]):把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
文件的打开与关闭
打开文件
在Python中,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件。
f = open('test.txt', 'w')
关闭文件
f = open('test.txt', 'w')
f.close()
路径说明
- 绝对路径:从盘符开始的路径
- 相对路径,相对当前源码所在的路径
绝对路径中为了不让\产生转义效果,需要在路径前天添加字符r,否则需要将每个\进行转义
f = open(r'E:\tmp\test.txt', 'w')
f.write('test')
f.close()
中文编码
在未指定写入字符集时,运行pycharm中编写的程序,输出中文到文件中,可能出现乱码情况,需要通过设置pycharm的默认字符集:文件-设置-编辑器-文件编码-项目编码,设置为UTF-8。
也可以在打开文件时通过encoding指定写入中文的字符集为UTF-8:
f = open(r'E:\tmp\test.txt', 'w', encoding='UTF-8')
f.write('test')
f.close()
文件读写
写
write
f = open(r'E:\tmp\test.txt', 'w', encoding='UTF-8')
f.write('test1')
f.close()
在同一个open文件的范围中,如果多次写入数据,那么是追加方式,如果在不同的open文件范围中,通过w方式进行写入是覆盖方式。
writelines
一次性写入多行
f = open(r'E:\tmp\test.txt', 'w', encoding='UTF-8')
# 通过换行符实现多行写入
f.write('test1\ntest2\ntest3\n')
#通过writelines一次性写出列表的每个元素
content = ['test1\n', 'test2\n', 'test3\n']
f.writelines(content)
# 使用字符串的join函数,为每个元素添加换行
content = ['test1', 'test2', 'test3']
f.write("\n".join(content))
f.close()
读
read
使用read(num)可以从文件中读取数据,num表示要从文件中读取的数据的长度(单位是字符),如果没有传入num,那么就表示读取文件中所有的数据。
如果一个文件被读了多次,那么后面一次读的起始位置是上一次读的结束位置。
f = open(r'E:\tmp\test.txt', 'r', encoding='UTF-8')
# data1 = f.read() # 未指定长度,读取所有数据
# print(data1)
# print('-------------')
data2 = f.read(2)
print(data2)
print('-------------')
data3 = f.read(3)
print(data3)
f.close()
readline
f = open(r'E:\tmp\test.txt', 'w', encoding='UTF-8')
f.write('test\n' * 10)
f.close()
f = open(r'E:\tmp\test.txt', 'r', encoding='UTF-8')
while True:
content = f.readline()
if content:
print(f"{content}",end="")
else:
break
f.close()
readlines
读取多行,一次性读取全部文件为列表,每行都是列表的一个字符串元素。
f = open(r'E:\tmp\test.txt', 'w', encoding='UTF-8')
f.write('test\n' * 10)
f.close()
f = open(r'E:\tmp\test.txt', 'r', encoding='UTF-8')
data = f.readlines()
print(data)
f.close()
所在位置(tell)
返回指针当前所在的位置(指针所在位置前面的字节数)。
f = open(r'E:\tmp\test.txt', 'w', encoding='UTF-8')
f.write('Hello, World!')
f.close()
f = open(r'E:\tmp\test.txt', 'r', encoding='UTF-8')
content = f.read(2) # 定位在2个字节后
print(content)
content = f.read(3) # 在两个字节后读取3个字节,当前定位应该在5
print(content)
print('当前指针位置:',f.tell())
f.close()
返回结果如下:
He
llo
当前指针位置: 5
定位(seek)
语法:
seek(offset[,whence])
解释:
offset:开始的偏移量,也就是代表需要移动偏移的字节数
whence:可选默认值为0,给offset参数一个定义,表示要从那个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起
f = open(r'E:\tmp\test.txt', 'w', encoding='UTF-8')
f.write('Hello, World!')
f.close()
f = open(r'E:\tmp\test.txt', 'r', encoding='UTF-8')
content = f.read(2) # 定位在2个字节后
print(content)
f.seek(3) # 直接定位在3个字节后
content = f.read(3) # 读取3个字节
print(content)
print('当前指针位置:',f.tell())
f.close()
返回结果如下:
He
lo,
当前指针位置: 6
访问模式
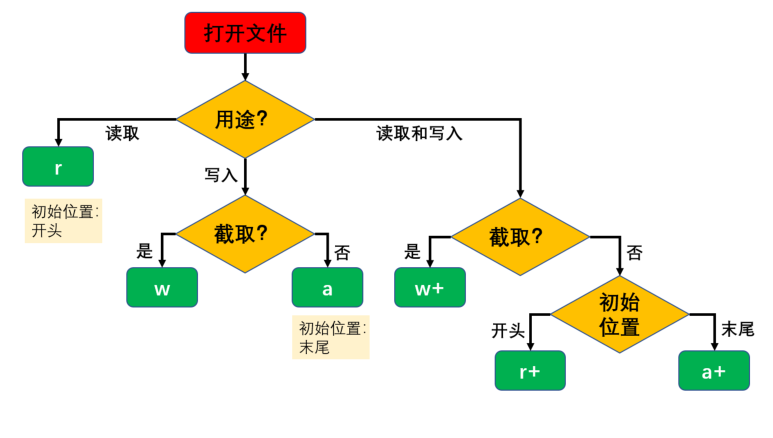
二进制读写
二进制文件的读写主要应用在图片、音乐、视频等文件的读写
- rb:read binary,读取二进制文件
- wb:write binary,写入二进制文件
将文件的内容单纯的用0和1来进行读取和存储。不用指定字符集。
文件对象的函数和属性
flush()刷新缓冲区
文件写入过程:数据-->缓冲区(内存中)-->文件中(硬盘上)
缓冲区清空的时间点:
- 当文件关闭的时候,自动清空缓冲区
- 当整个程序运行结束的时候自动清空缓冲区
- 当缓冲区写满了,会自动清空缓冲区
- 手动清空缓冲区
truncate()截断文件
truncate函数,从指针位置到结束的字符全部删除掉,只保留指针之前的内容。
文件对象
文件对象是一个可迭代对象;可以直接通过遍历访问到每一行内容
f = open(r'E:\tmp\test.txt', 'r', encoding='UTF-8')
for line in f: # 循环文件每一行的内容
print(line)
# 可以通过文件对象的方法获取文件的属性及状态
print("文件名:", f.name)
print("文件的打开模式:", f.mode)
print("文件可写:", f.writable())
print("文件可读:", f.readable())
f.close()
返回结果如下:
Hello, World!
文件名: E:\tmp\test.txt
文件的打开模式: r
文件可写: False
文件可读: True

