
说明
本文主要对一下内容进行说明
- 云原生、容器场景下监控的挑战;
- Prometheus服务发现的实现机制;
- Prometheus中服务发现的几种实现方式;
- Prometheus中强大的Relabel机制。
Prometheus与服务发现
在基于云(IaaS或者CaaS)的基础设施环境中用户可以像使用水、电一样按需使用各种资源(计算、网络、存储)。按需使用就意味着资源的动态性,这些资源可以随着需求规模的变化而变化。例如在AWS中就提供了专门的AutoScall服务,可以根据用户定义的规则动态地创建或者销毁EC2实例,从而使用户部署在AWS上的应用可以自动的适应访问规模的变化。
这种按需的资源使用方式对于监控系统而言就意味着没有了一个固定的监控目标,所有的监控对象(基础设施、应用、服务)都在动态的变化。对于Nagias这类基于Push模式传统监控软件就意味着必须在每一个节点上安装相应的Agent程序,并且通过配置指向中心的Nagias服务,受监控的资源与中心监控服务器之间是一个强耦合的关系,要么直接将Agent构建到基础设施镜像当中,要么使用一些自动化配置管理工具(如Ansible、Chef)动态的配置这些节点。当然实际场景下除了基础设施的监控需求以外,我们还需要监控在云上部署的应用,中间件等等各种各样的服务。要搭建起这样一套中心化的监控系统实施成本和难度是显而易见的。
而对于Prometheus这一类基于Pull模式的监控系统,显然也无法继续使用的static_configs的方式静态的定义监控目标。而对于Prometheus而言其解决方案就是引入一个中间的代理人(服务注册中心),这个代理人掌握着当前所有监控目标的访问信息,Prometheus只需要向这个代理人询问有哪些监控目标控即可, 这种模式被称为服务发现。
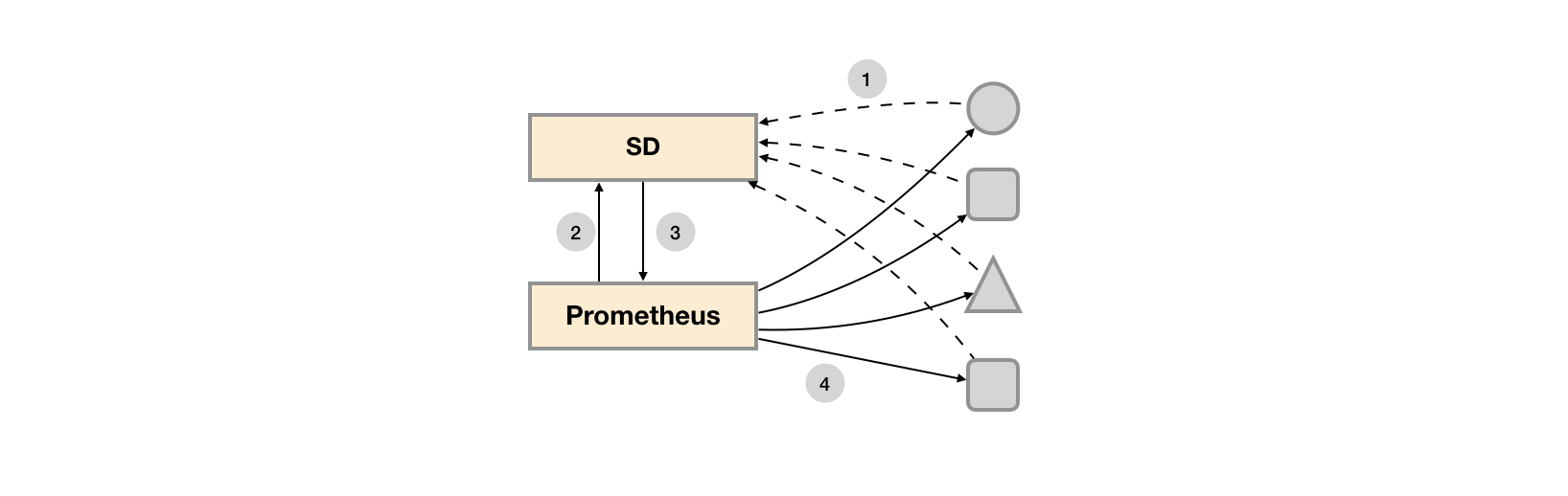
在不同的场景下,会有不同的东西扮演者代理人(服务发现与注册中心)这一角色。比如在AWS公有云平台或者OpenStack的私有云平台中,由于这些平台自身掌握着所有资源的信息,此时这些云平台自身就扮演了代理人的角色。Prometheus通过使用平台提供的API就可以找到所有需要监控的云主机。在Kubernetes这类容器管理平台中,Kubernetes掌握并管理着所有的容器以及服务信息,那此时Prometheus只需要与Kubernetes打交道就可以找到所有需要监控的容器以及服务对象。Prometheus还可以直接与一些开源的服务发现工具进行集成,例如在微服务架构的应用程序中,经常会使用到例如Consul这样的服务发现注册软件,Promethues也可以与其集成从而动态的发现需要监控的应用服务实例。除了与这些平台级的公有云、私有云、容器云以及专门的服务发现注册中心集成以外,Prometheus还支持基于DNS以及文件的方式动态发现监控目标,从而大大的减少了在云原生,微服务以及云模式下监控实施难度。
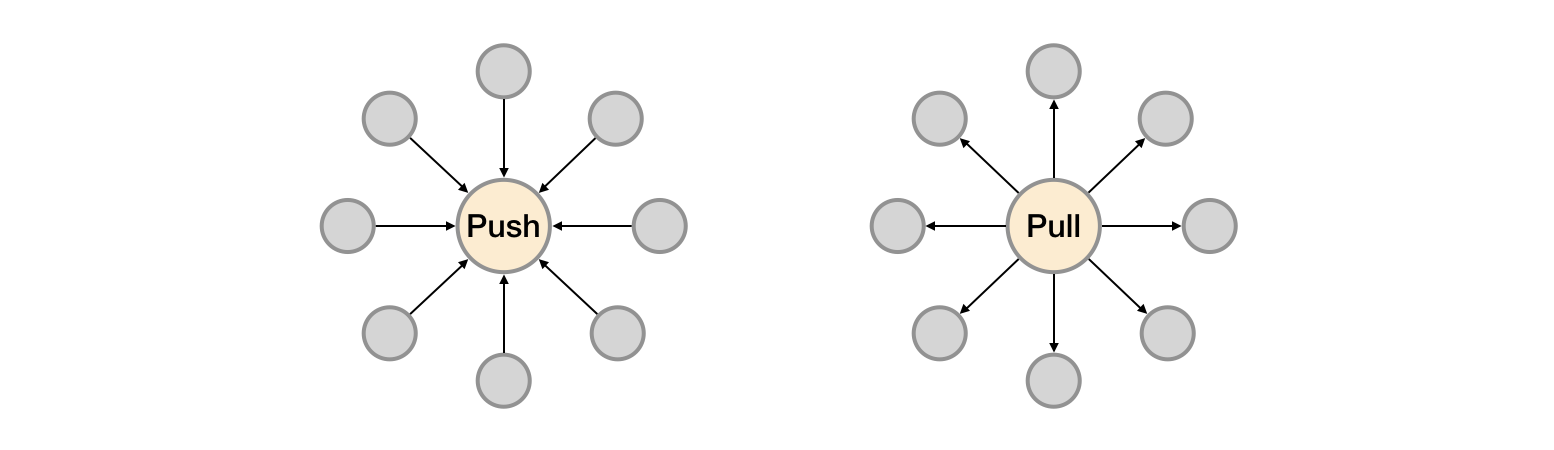
如上所示,展示了Push系统和Pull系统的核心差异。相较于Push模式,Pull模式的优点可以简单总结为以下几点:
- 只要Exporter在运行,你可以在任何地方(比如在本地),搭建你的监控系统;
- 你可以更容易的查看监控目标实例的健康状态,并且可以快速定位故障;
- 更利于构建DevOps文化的团队;
- 松耦合的架构模式更适合于云原生的部署环境。
基于静态配置的服务发现:static_configs
在prometheus配置文件中配置
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'grafana'
static_configs:
- targets:
- 'grafana-service.ns-monitor:3000'
- job_name: 'kubernetes-apiservers'
基于文件的服务发现:file_sd_configs
在Prometheus支持的众多服务发现的实现方式中,基于文件的服务发现是最通用的方式。这种方式不需要依赖于任何的平台或者第三方服务。对于Prometheus而言也不可能支持所有的平台或者环境。通过基于文件的服务发现方式下,Prometheus会定时从文件中读取最新的Target信息,因此,你可以通过任意的方式将监控Target的信息写入即可。
用户可以通过JSON或者YAML格式的文件,定义所有的监控目标。例如,在下面的JSON文件中分别定义了3个采集任务,以及每个任务对应的Target列表:
[
{
"targets": [ "localhost:8080"],
"labels": {
"env": "localhost",
"job": "cadvisor"
}
},
{
"targets": [ "localhost:9104" ],
"labels": {
"env": "prod",
"job": "mysqld"
}
},
{
"targets": [ "localhost:9100"],
"labels": {
"env": "prod",
"job": "node"
}
}
]
同时还可以通过为这些实例添加一些额外的标签信息,例如使用env标签标示当前节点所在的环境,这样从这些实例中采集到的样本信息将包含这些标签信息,从而可以通过该标签按照环境对数据进行统计。
创建Prometheus配置文件/etc/prometheus/prometheus-file-sd.yml,并添加以下内容:
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 15s
scrape_configs:
- job_name: 'file_ds'
file_sd_configs:
- files:
- targets.json
这里定义了一个基于file_sd_configs的监控采集任务,其中模式的任务名称为file_ds。在JSON文件中可以使用job标签覆盖默认的job名称,此时启动Prometheus服务:
prometheus --config.file=/etc/prometheus/prometheus-file-sd.yml --storage.tsdb.path=/data/prometheus
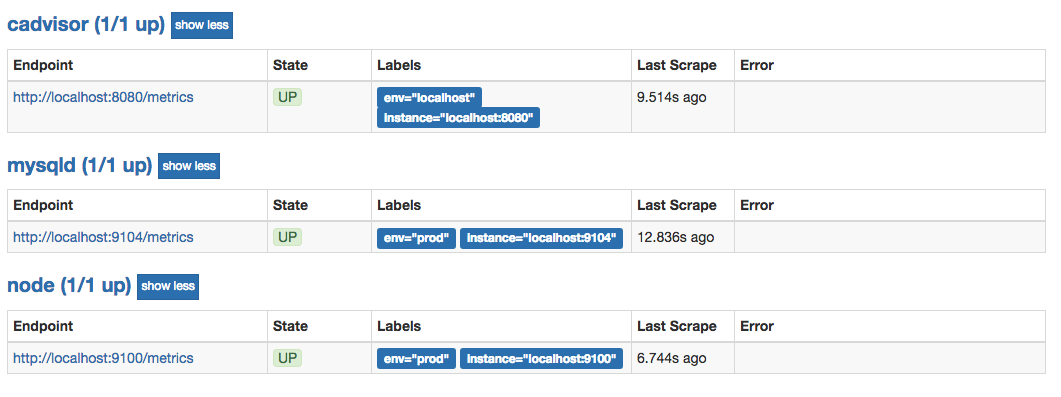
在Prometheus UI的Targets下就可以看到当前从targets.json文件中动态获取到的Target实例信息以及监控任务的采集状态,同时在Labels列下会包含用户添加的自定义标签:
Prometheus默认每5m重新读取一次文件内容,当需要修改时,可以通过refresh_interval进行设置,例如:
- job_name: 'file_ds'
file_sd_configs:
- refresh_interval: 1m
files:
- targets.json
通过这种方式,Prometheus会自动的周期性读取文件中的内容。当文件中定义的内容发生变化时,不需要对Prometheus进行任何的重启操作。
这种通用的方式可以衍生了很多不同的玩法,比如与自动化配置管理工具(Ansible)结合、与Cron Job结合等等。 对于一些Prometheus还不支持的云环境,比如国内的阿里云、腾讯云等也可以使用这种方式通过一些自定义程序与平台进行交互自动生成监控Target文件,从而实现对这些云环境中基础设施的自动化监控支持。
基于dns的服务发现:dns_sd_configs
略
基于kubernetes的服务发现:kubernetes_sd_configs
对于kubernetes而言,Promethues通过与Kubernetes API交互,然后轮询资源端点。目前主要支持5种服务发现模式,分别是:
Node
node角色可以发现集群中每个node节点的地址端口,默认为Kubelet的HTTP端口。目标地址默认为Kubernetes节点对象的第一个现有地址,地址类型顺序为NodeInternalIP、NodeExternalIP、NodeLegacyHostIP和NodeHostName。
作用:监控K8S的node节点的服务器相关的指标数据。
Service
service角色可以发现每个service的ip和port,将其作为target。这对于黑盒监控(blackbox)很有用。
Pod
pod角色可以发现所有pod并将其中的pod ip作为target。如果有多个端口或者多个容器,将生成多个target(例如:80,443这两个端口,pod ip为10.0.244.22,则将10.0.244.22:80,10.0.244.22:443分别作为抓取的target)。
如果容器没有指定的端口,则会为每个容器创建一个无端口target,以便通过relabel手动添加端口。
Endpoints
endpoints角色可以从ep(endpoints)列表中发现所有targets。
- 如果ep是属于service的话,则会附加service角色的所有标签
- 对于ep的后端节点是pod,则会附加pod角色的所有标签(即上边介绍的pod角色可用标签)
比如我么手动创建一个ep,这个ep关联到一个pod,则prometheus的标签中会包含这个pod角色的所有标签
Ingress
ingress角色发现ingress的每个路径的target。这通常对黑盒监控很有用。该地址将设置为ingress中指定的host。
说明
# Kubernetes的API SERVER会暴露API服务,Promethues集成了对Kubernetes的自动发现,它有5种模式:Node、Service、Pod、Endpoints、ingress,下面是Prometheus官方给出的对Kubernetes服务发现的实例。这里你会看到大量的relabel_configs,其实你就是把所有的relabel_configs去掉一样可以对kubernetes做服务发现。relabel_configs仅仅是对采集过来的指标做二次处理,比如要什么不要什么以及替换什么等等。而以__meta_开头的这些元数据标签都是实例中包含的,而relabel则是动态的修改、覆盖、添加删除这些标签或者这些标签对应的值。而且以__开头的标签通常是系统内部使用的,因此这些标签不会被写入样本数据中,如果我们要收集这些东西那么则要进行relabel操作。当然reabel操作也不仅限于操作__开头的标签。
# action的行为:
# replace:默认行为,不配置action的话就采用这种行为,它会根据regex来去匹配source_labels标签上的值,并将并将匹配到的值写入target_label中
# labelmap:它会根据regex去匹配标签名称,并将匹配到的内容作为新标签的名称,其值作为新标签的值
# keep:仅收集匹配到regex的源标签,而会丢弃没有匹配到的所有标签,用于选择
# drop:丢弃匹配到regex的源标签,而会收集没有匹配到的所有标签,用于排除
# labeldrop:使用regex匹配标签,符合regex规则的标签将从target实例中移除,其实也就是不收集不保存
# labelkeep:使用regex匹配标签,仅收集符合regex规则的标签,不符合的不收集
global:
# 间隔时间
scrape_interval: 30s
# 超时时间
scrape_timeout: 10s
# 另一个独立的规则周期,对告警规则做定期计算
evaluation_interval: 30s
# 外部系统标签
external_labels:
prometheus: monitoring/k8s
prometheus_replica: prometheus-k8s-1
# 抓取服务端点,整个这个任务都是用来发现node-exporter和kube-state-metrics-service的,这里用的是endpoints角色,这是通过这两者的service来发现
# 的后端endpoints。另外需要说明的是如果满足采集条件,那么在service、POD中定义的labels也会被采集进去
scrape_configs:
# 定义job名称,是一个拉取单元
- job_name: "kubernetes-endpoints"
# 发现endpoints,它是从列出的服务端点发现目标,这个endpoints来自于Kubernetes中的service,每一个service都有对应的endpoints,这里是一个列表
# 可以是一个IP:PORT也可以是多个,这些IP:PORT就是service通过标签选择器选择的POD的IP和端口。所以endpoints角色就是用来发现server对应的pod的IP的
# kubernetes会有一个默认的service,通过找到这个service的endpoints就找到了api server的IP:PORT,那endpoints有很多,我怎么知道哪个是api server呢
# 这个就靠source_labels指定的标签名称了。
kubernetes_sd_configs:
# 角色为 endpoints
- role: endpoints
relabel_configs:
# 重新打标仅抓取到的具有 "prometheus.io/scrape: true" 的annotation的端点,意思是说如果某个service具有prometheus.io/scrape = true annotation声明则抓取
# annotation本身也是键值结构,所以这里的源标签设置为键,而regex设置值,当值匹配到regex设定的内容时则执行keep动作也就是保留,其余则丢弃.
# node-exporter这个POD的service里面就有一个叫做prometheus.io/scrape = true的annotations所以就找到了node-exporter这个POD
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
# 动作 删除 regex 与串联不匹配的目标 source_labels
action: keep
# 通过正式表达式匹配 true
regex: true
# 重新设置scheme
# 匹配源标签__meta_kubernetes_service_annotation_prometheus_io_scheme也就是prometheus.io/scheme annotation
# 如果源标签的值匹配到regex则把值替换为__scheme__对应的值
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
# 匹配来自 pod annotationname prometheus.io/path 字段
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
# 获取POD的 annotation 中定义的"prometheus.io/path: XXX"定义的值,这个值就是你的程序暴露符合prometheus规范的metrics的地址
# 如果你的metrics的地址不是 /metrics 的话,通过这个标签说,那么这里就会把这个值赋值给 __metrics_path__这个变量,因为prometheus
# 是通过这个变量获取路径然后进行拼接出来一个完整的URL,并通过这个URL来获取metrics值的,因为prometheus默认使用的就是 http(s)://X.X.X.X/metrics
# 这样一个路径来获取的。
action: replace
# 匹配目标指标路径
target_label: __metrics_path__
# 匹配全路径
regex: (.+)
# 匹配出 Pod ip地址和 Port
- source_labels:
[__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::d+)?;(d+)
replacement: $1:$2
# 下面主要是为了给样本添加额外信息
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
# 元标签 服务对象的名称空间
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
# service 对象的名称
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
# pod对象的名称
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
基于Consul的服务发现:consul_sd_configs
Consul是由HashiCorp开发的一个支持多数据中心的分布式服务发现和键值对存储服务的开源软件,被大量应用于基于微服务的软件架构当中。
Consul
用户可以通过Consul官网https://www.consul.io/downloads.html下载对应操作系统版本的软件包。Consul与Prometheus同样使用Go语言进行开发,因此安装和部署的方式也极为简单,解压并将命令行工具放到系统PATH路径下即可。
在本地可以使用开发者模式在本地快速启动一个单节点的Consul环境:
$ consul agent -dev
==> Starting Consul agent...
==> Consul agent running!
Version: 'v1.0.7'
Node ID: 'd7b590ba-e2f8-3a82-e8a8-2a911bdf67d5'
Node name: 'localhost'
Datacenter: 'dc1' (Segment: '<all>')
Server: true (Bootstrap: false)
Client Addr: [127.0.0.1] (HTTP: 8500, HTTPS: -1, DNS: 8600)
Cluster Addr: 127.0.0.1 (LAN: 8301, WAN: 8302)
Encrypt: Gossip: false, TLS-Outgoing: false, TLS-Incoming: false
在启动成功后,在一个新的terminal窗口中运行consul members可以查看当前集群中的所有节点:
$ consul members
Node Address Status Type Build Protocol DC Segment
localhost 127.0.0.1:8301 alive server 1.0.7 2 dc1 <all>
用户还可以通过HTTP API的方式查看当前集群中的节点信息:
$ curl localhost:8500/v1/catalog/nodes
[
{
"ID": "d7b590ba-e2f8-3a82-e8a8-2a911bdf67d5",
"Node": "localhost",
"Address": "127.0.0.1",
"Datacenter": "dc1",
"TaggedAddresses": {
"lan": "127.0.0.1",
"wan": "127.0.0.1"
},
"Meta": {
"consul-network-segment": ""
},
"CreateIndex": 5,
"ModifyIndex": 6
}
]
Consul还提供了内置的DNS服务,可以通过Consul的DNS服务的方式访问其中的节点:
$ dig @127.0.0.1 -p 8600 localhost.node.consul
; <<>> DiG 9.9.7-P3 <<>> @127.0.0.1 -p 8600 localhost.node.consul
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 50684
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;localhost.node.consul. IN A
;; ANSWER SECTION:
localhost.node.consul. 0 IN A 127.0.0.1
;; Query time: 5 msec
;; SERVER: 127.0.0.1#8600(127.0.0.1)
;; WHEN: Sun Apr 15 22:10:56 CST 2018
;; MSG SIZE rcvd: 66
在Consul当中服务可以通过服务定义文件或者是HTTP API的方式进行注册。这里使用服务定义文件的方式将本地运行的node_exporter通过服务的方式注册到Consul当中。
创建配置目录:
sudo mkdir /etc/consul.d
echo '{"service": {"name": "node_exporter", "tags": ["exporter"], "port": 9100}}' \
| sudo tee /etc/consul.d/node_exporter.json |
| ----------------------------------------- |
重新启动Consul服务,并且声明服务定义文件所在目录:
$ consul agent -dev -config-dir=/etc/consul.d
==> Starting Consul agent...
2018/04/15 22:23:47 [DEBUG] agent: Service "node_exporter" in sync
一旦服务注册成功之后,用户就可以通过DNS或HTTP API的方式查询服务信息。默认情况下,所有的服务都可以使用NAME.service.consul域名的方式进行访问。
例如,可以使用node_exporter.service.consul域名查询node_exporter服务的信息:
$ dig @127.0.0.1 -p 8600 node_exporter.service.consul
;; QUESTION SECTION:
;node_exporter.service.consul. IN A
;; ANSWER SECTION:
node_exporter.service.consul. 0 IN A 127.0.0.1
如上所示DNS记录会返回当前可用的node_exporter服务实例的IP地址信息。
除了使用DNS的方式以外,Consul还支持用户使用HTTP API的形式获取服务列表:
$ curl http://localhost:8500/v1/catalog/service/node_exporter
[
{
"ID": "e561b376-2c1b-653d-61a0-1d844bce06a7",
"Node": "localhost",
"Address": "127.0.0.1",
"Datacenter": "dc1",
"TaggedAddresses": {
"lan": "127.0.0.1",
"wan": "127.0.0.1"
},
"NodeMeta": {
"consul-network-segment": ""
},
"ServiceID": "node_exporter",
"ServiceName": "node_exporter",
"ServiceTags": [
"exporter"
],
"ServiceAddress": "",
"ServiceMeta": {},
"ServicePort": 9100,
"ServiceEnableTagOverride": false,
"CreateIndex": 6,
"ModifyIndex": 6
}
]
Consul也提供了一个Web UI可以查看Consul中所有服务以及节点的状态:
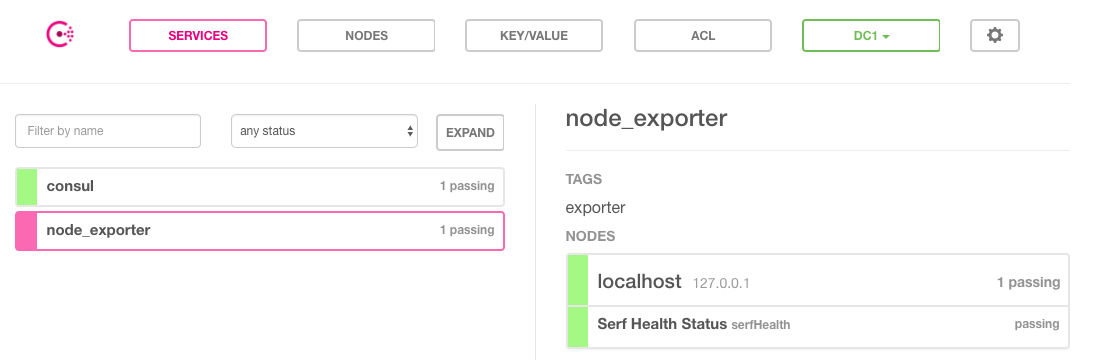
当然Consul还提供了更多的API用于支持对服务的生命周期管理(添加、删除、修改等)这里就不做过多的介绍,感兴趣的同学可以通过Consul官方文档了解更多的详细信息。
与Prometheus集成
Consul作为一个通用的服务发现和注册中心,记录并且管理了环境中所有服务的信息。Prometheus通过与Consul的交互可以获取到相应Exporter实例的访问信息。在Prometheus的配置文件当可以通过以下方式与Consul进行集成:
- job_name: node_exporter
metrics_path: /metrics
scheme: http
consul_sd_configs:
- server: localhost:8500
services:
- node_exporter
在consul_sd_configs定义当中通过server定义了Consul服务的访问地址,services则定义了当前需要发现哪些类型服务实例的信息,这里限定了只获取node_exporter的服务实例信息。
服务发现与Relabeling
通过服务发现的方式,管理员可以在不重启Prometheus服务的情况下动态的发现需要监控的Target实例信息。
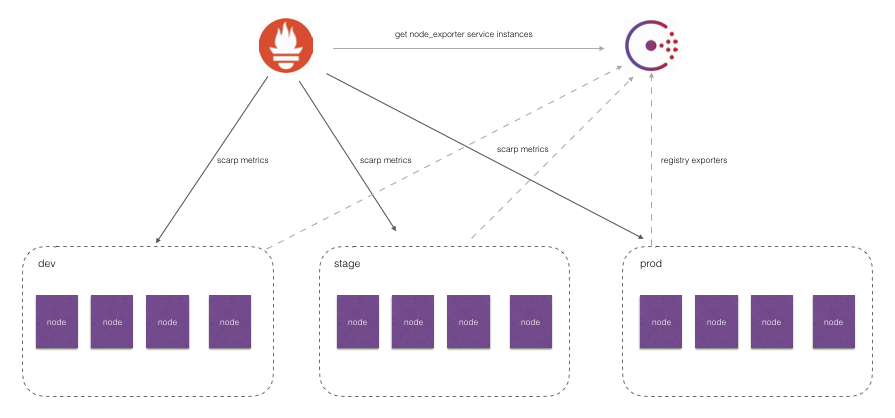
如上图所示,对于线上环境我们可能会划分为:dev, stage, prod不同的集群。每一个集群运行多个主机节点,每个服务器节点上运行一个Node Exporter实例。Node Exporter实例会自动注册到Consul中,而Prometheus则根据Consul返回的Node Exporter实例信息动态的维护Target列表,从而向这些Target轮询监控数据。
然而,如果我们可能还需要:
按照不同的环境dev, stage, prod聚合监控数据?
对于研发团队而言,我可能只关心dev环境的监控数据,如何处理?
如果为每一个团队单独搭建一个Prometheus Server。那么如何让不同团队的Prometheus Server采集不同的环境监控数据?
面对以上这些场景下的需求时,我们实际上是希望Prometheus Server能够按照某些规则(比如标签)从服务发现注册中心返回的Target实例中有选择性的采集某些Exporter实例的监控数据。
可以通过Prometheus强大的Relabel机制来实现以上这些具体的目标。
Prometheus的Relabeling机制
在Prometheus所有的Target实例中,都包含一些默认的Metadata标签信息。可以通过Prometheus UI的Targets页面中查看这些实例的Metadata标签的内容:

默认情况下,当Prometheus加载Target实例完成后,这些Target时候都会包含一些默认的标签:
__address__:当前Target实例的访问地址<host>:<port>__scheme__:采集目标服务访问地址的HTTP Scheme,HTTP或者HTTPS__metrics_path__:采集目标服务访问地址的访问路径__param_<name>:采集任务目标服务的中包含的请求参数
上面这些标签将会告诉Prometheus如何从该Target实例中获取监控数据。除了这些默认的标签以外,我们还可以为Target添加自定义的标签,例如,基于文件的服务发现通过JSON配置文件,为Target实例添加了自定义标签env,如下所示该标签最终也会保存到从该实例采集的样本数据中:
node_cpu{cpu="cpu0",env="prod",instance="localhost:9100",job="node",mode="idle"}
一般来说,Target以__作为前置的标签是在系统内部使用的,因此这些标签不会被写入到样本数据中。不过这里有一些例外,例如,我们会发现所有通过Prometheus采集的样本数据中都会包含一个名为instance的标签,该标签的内容对应到Target实例的__address__。 这里实际上是发生了一次标签的重写处理。
这种发生在采集样本数据之前,对Target实例的标签进行重写的机制在Prometheus被称为Relabeling。

Prometheus允许用户在采集任务设置中通过relabel_configs来添加自定义的Relabeling过程。
使用replace/labelmap重写标签
Relabeling最基本的应用场景就是基于Target实例中包含的metadata标签,动态的添加或者覆盖标签。例如,通过Consul动态发现的服务实例还会包含以下Metadata标签信息:
__meta_consul_address:consul地址__meta_consul_dc:consul中服务所在的数据中心__meta_consulmetadata:服务的metadata__meta_consul_node:服务所在consul节点的信息__meta_consul_service_address:服务访问地址__meta_consul_service_id:服务ID__meta_consul_service_port:服务端口__meta_consul_service:服务名称__meta_consul_tags:服务包含的标签信息
在默认情况下,从Node Exporter实例采集上来的样本数据如下所示:
node_cpu{cpu="cpu0",instance="localhost:9100",job="node",mode="idle"} 93970.8203125
我们希望能有一个额外的标签dc可以表示该样本所属的数据中心:
node_cpu{cpu="cpu0",instance="localhost:9100",job="node",mode="idle", dc="dc1"} 93970.8203125
在每一个采集任务的配置中可以添加多个relabel_config配置,一个最简单的relabel配置如下:
scrape_configs:
- job_name: node_exporter
consul_sd_configs:
- server: localhost:8500
services:
- node_exporter
relabel_configs:
- source_labels: ["__meta_consul_dc"]
target_label: "dc"
该采集任务通过Consul动态发现Node Exporter实例信息作为监控采集目标。在上述内容中通过Consul动态发现的监控Target都会包含一些额外的Metadata标签,比如标签__meta_consul_dc表明了当前实例所在的Consul数据中心,因此我们希望从这些实例中采集到的监控样本中也可以包含这样一个标签,例如:
node_cpu{cpu="cpu0",dc="dc1",instance="172.21.0.6:9100",job="consul_sd",mode="guest"}
这样可以方便的根据dc标签的值,根据不同的数据中心聚合分析各自的数据。
在这个例子中,通过从Target实例中获取__meta_consul_dc的值,并且重写所有从该实例获取的样本中。
完整的relabel_config配置如下所示:
# The source labels select values from existing labels. Their content is concatenated
# using the configured separator and matched against the configured regular expression
# for the replace, keep, and drop actions.
[ source_labels: '[' <labelname> [, ...] ']' ]
# Separator placed between concatenated source label values.
[ separator: <string> | default = ; ]
# Label to which the resulting value is written in a replace action.
# It is mandatory for replace actions. Regex capture groups are available.
[ target_label: <labelname> ]
# Regular expression against which the extracted value is matched.
[ regex: <regex> | default = (.*) ]
# Modulus to take of the hash of the source label values.
[ modulus: <uint64> ]
# Replacement value against which a regex replace is performed if the
# regular expression matches. Regex capture groups are available.
[ replacement: <string> | default = $1 ]
# Action to perform based on regex matching.
[ action: <relabel_action> | default = replace ]
relabel_action说明:
replace: Match regex against the concatenated source_labels. Then, set target_label to replacement, with match group references (${1}, ${2}, ...) in replacement substituted by their value. If regex does not match, no replacement takes place.
lowercase: Maps the concatenated source_labels to their lower case.
uppercase: Maps the concatenated source_labels to their upper case.
keep: Drop targets for which regex does not match the concatenated source_labels.
drop: Drop targets for which regex matches the concatenated source_labels.
keepequal: Drop targets for which the concatenated source_labels do not match target_label.
dropequal: Drop targets for which the concatenated source_labels do match target_label.
hashmod: Set target_label to the modulus of a hash of the concatenated source_labels.
labelmap: Match regex against all source label names, not just those specified in source_labels. Then copy the values of the matching labels to label names given by replacement with match group references (${1}, ${2}, ...) in replacement substituted by their value.
labeldrop: Match regex against all label names. Any label that matches will be removed from the set of labels.
labelkeep: Match regex against all label names. Any label that does not match will be removed from the set of labels.
其中action定义了当前relabel_config对Metadata标签的处理方式,默认的action行为为replace。 replace行为会根据regex的配置匹配source_labels标签的值(多个source_label的值会按照separator进行拼接),并且将匹配到的值写入到target_label当中,如果有多个匹配组,则可以使用{1}, {2}确定写入的内容。如果没匹配到任何内容则不对target_label进行重新。
repalce操作允许用户根据Target的Metadata标签重写或者写入新的标签键值对,在多环境的场景下,可以帮助用户添加与环境相关的特征维度,从而可以更好的对数据进行聚合。
除了使用replace以外,还可以定义action的配置为labelmap。与replace不同的是,labelmap会根据regex的定义去匹配Target实例所有标签的名称,并且以匹配到的内容为新的标签名称,其值作为新标签的值。
例如,在监控Kubernetes下所有的主机节点时,为将这些节点上定义的标签写入到样本中时,可以使用如下relabel_config配置:
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
而使用labelkeep或者labeldrop则可以对Target标签进行过滤,仅保留符合过滤条件的标签,例如:
relabel_configs:
- regex: label_should_drop_(.+)
action: labeldrop
该配置会使用regex匹配当前Target实例的所有标签,并将符合regex规则的标签从Target实例中移除。labelkeep正好相反,会移除那些不匹配regex定义的所有标签。
使用keep/drop过滤Target实例
在上一部分中我们介绍了Prometheus的Relabeling机制,并且使用了replace/labelmap/labelkeep/labeldrop对标签进行管理。而本节开头还提到过第二个问题,使用中心化的服务发现注册中心时,所有环境的Exporter实例都会注册到该服务发现注册中心中。而不同职能(开发、测试、运维)的人员可能只关心其中一部分的监控数据,他们可能各自部署的自己的Prometheus Server用于监控自己关心的指标数据,如果让这些Prometheus Server采集所有环境中的所有Exporter数据显然会存在大量的资源浪费。如何让这些不同的Prometheus Server采集各自关心的内容?答案还是Relabeling,relabel_config的action除了默认的replace以外,还支持keep/drop行为。例如,如果我们只希望采集数据中心dc1中的Node Exporter实例的样本数据,那么可以使用如下配置:
scrape_configs:
- job_name: node_exporter
consul_sd_configs:
- server: localhost:8500
services:
- node_exporter
relabel_configs:
- source_labels: ["__meta_consul_dc"]
regex: "dc1"
action: keep
当action设置为keep时,Prometheus会丢弃source_labels的值中没有匹配到regex正则表达式内容的Target实例,而当action设置为drop时,则会丢弃那些source_labels的值匹配到regex正则表达式内容的Target实例。可以简单理解为keep用于选择,而drop用于排除。
使用hashmod计算source_labels的Hash值
当relabel_config设置为hashmod时,Prometheus会根据modulus的值作为系数,计算source_labels值的hash值。例如:
scrape_configs
- job_name: 'file_ds'
relabel_configs:
- source_labels: [__address__]
modulus: 4
target_label: tmp_hash
action: hashmod
file_sd_configs:
- files:
- targets.json
根据当前Target实例__address__的值以4作为系数,这样每个Target实例都会包含一个新的标签tmp_hash,并且该值的范围在1~4之间,查看Target实例的标签信息,可以看到如下的结果,每一个Target实例都包含了一个新的tmp_hash值:

利用Hashmod的能力在Target实例级别实现对采集任务的功能分区的:
scrape_configs:
- job_name: some_job
relabel_configs:
- source_labels: [__address__]
modulus: 4
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$
action: keep
这里需要注意的是,如果relabel的操作只是为了产生一个临时变量,以作为下一个relabel操作的输入,那么我们可以使用__tmp作为标签名的前缀,通过该前缀定义的标签就不会写入到Target或者采集到的样本的标签中。
当prometheus需要采集的数据超过其承载能力时,可以通过hashmod对需要采集的target做散列,然后启用多个prometheus server来进行采集。
- 比如启用4个prometheus server来进行采集,那么可以将所有需要采集的target放置于共享存储中,每个prometheus server读取的target都是一样的。
- 然后在按照上方hashmod规则,将target分散为4份(0-3),然后每个prometheus server通过不同的regex进行匹配0-3的值,并将未匹配上的target丢弃。此时server[0-3]采集散列值为[0-3]的target。
- 这样就可以实现对target的集中管理,但prometheus server又大致处于均衡负载的环境。
- 在通过prometheus 相关的一些集群方案将数据聚合进行分析。
文档来源
https://www.prometheus.wang/sd/
https://www.cnblogs.com/zhangpeiyao/p/17242200.html


